什么是 Kafka
Kafka 最初由 Linkedin 公司开发,是一个分布式的、_分区的_、_多副本的_、_多订阅者_,基于 zookeeper 协调的分布式日志系统(也可以当做 MQ 系统),常用于 web/nginx 日志、访问日志、消息服务等等,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
- 高吞吐量、低延迟:kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
- 可扩展性:kafka 集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止丢失;
- 容错性:允许集群中的节点失败(若分区副本数量为 n,则允许 n-1 个节点失败);
- 高并发:单机可支持数千个客户端同时读写;
下载完成之后,打开config文件夹,简单更改一下配置文件。
找到zookeeper.properties进行修改
#zookeeper运行时产生的文件存放路径,win可能需要注意 dataDir=/tmp/zookeeper找到server.properties进行修改
#kafka运行时日志文件存放路径 log.dirs=/tmp/kafka-logs #kafka组id group.id=test-consumer-group
完成后,以正确的顺序启动所有服务:
# Start the ZooKeeper service
# Note: Soon, ZooKeeper will no longer be required by Apache Kafka.
$ bin/zookeeper-server-start.sh config/zookeeper.properties打开另一个终端:
# Start the Kafka broker service
$ bin/kafka-server-start.sh config/server.properties成功启动所有服务后,您将运行并可以使用基本的 Kafka 环境。
SpringBoot 中使用 Kafka
1. 添加所需要的依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>2. Kafka 的部分配置
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=112.126.74.249:9092,112.126.74.249:9093
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
# 事务初始化 设置为一个非空的字符串即可开启事务功能
spring.kafka.producer.transaction-id-prefix=transaction
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
# 设置批量消费
# spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
# spring.kafka.consumer.max-poll-records=50
#==================================================
#一般来说 配置一下就行
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: test-consumer-group
enable-auto-commit: true
auto-commit-interval: 30003. 生产者
//生产者
@Component
public class EventProducet {
@Autowired
private KafkaTemplate kafkaTemplate;//也可以通过<T, T>的方式来指定类型,默认都是String
//发送事件
public void fireEvent(Event event){
//将事件发布到指定主题 这里是封装了一个事件类,发布事件时将事件类转换成JSON
kafkaTemplate.send("topic1", JSONObject.toJSONString(event));
}
}
//生产者
@Component
class KafkaProducer{
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic,String content){
kafkaTemplate.send(topic,content);
}
}4. 消费者
@Component
public class KafkaConsumer {
// 消费监听
@KafkaListener(topics = {"topic1"})
public void onMessage1(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("============"+record.topic()+"->"+record.partition()+"->"+record.value()+"============");
}
}上面的实例创建了一个生产者,发送消息到topic1,然后又一个消费者监听topic1,监听用 @KafkaListener注解,topic 表示要监听的 topic,支持同时监听多个,有逗号分隔
创建一个测试类进行测试
@SpringBootTest
public class KafkaTest {
@Autowired
KafkaProducer kafkaProducer;
@Test
public void testKafka() throws InterruptedException {
kafkaProducer.sendMessage("topic1", "Hello");
kafkaProducer.sendMessage("topic1", "World");
Thread.sleep(1000*10);
}
}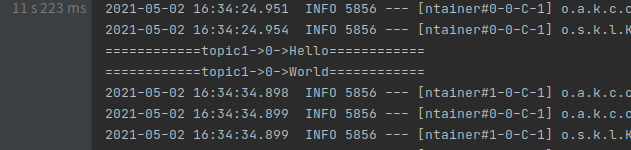
可以看到成功运行
最简单的应用便到此结束
生产者的更多使用方法
1. 待回调的生产者
Kafka 提供了一个回调方法 addCallback,我们可以在回调方法中监控信息是否发送成功或失败做补偿处理,有两种写法
@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
kafkaTemplate.send(topic, content).addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
System.out.println("发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("发送消息成功:" + result.getRecordMetadata().topic() + "-"
+ result.getRecordMetadata().partition() + "-" + result.getRecordMetadata().offset() + "-" + result.getProducerRecord().value());
}
});
}
}@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
ListenableFuture<SendResult<String,String>> future = kafkaTemplate.send(topic, content);
future.addCallback((result)-> {
// 消息发送到的topic
String tp = result.getRecordMetadata().topic();
// 消息发送到的分区
int partition = result.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = result.getRecordMetadata().offset();
System.out.println("发送消息成功:" + tp + "-" + partition + "-" + offset);
}, (KafkaFailureCallback<Integer, String>) ex -> {
ProducerRecord<Integer, String> failed = ex.getFailedProducerRecord();
});
}
}2. 自定义分区
kafka 中每个 topic 划分了多个分区,那么生产者将消息发送到 topic 时,具体追加到那个分区呢?这就是所谓的分区策略,kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略,其路由机制为:
- 若发送消息时指定了分区(即自定义分区策略),则直接将消息 append 到指定分区。
- 若发送消息时未指定 partition,但指定了 key(kafka 允许为每条消息设置一个 key),则对 key 值进行 hash 计算,根据计算结构路由到指定分区,这种情况下可以保证同一个 key 的所有消息都进入相同的分区。
partition 和 key 都未指定,则使用 kafka 默认的分区策略,轮询出一个 partition
自定义一个分区策略,将消息发送到我们指定的 partition,首先建立一个分区器类实现 Partitioner 接口,重写方法,其中 partition 方法的返回值表示将消息发送到几号分区。
public class CustomizePartitioner implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
// 自定义分区规则(这里假设全部发到0号分区)
// ......
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
3. kafka 事务提交
如果发送消息时需要创建事务,可以使用 kafkaTemplate 的 executeInTransaction 方法来声明事务。
需要先进行配置 yml
spring.kafka.producer.transaction-id-prefix=transaction@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback() {
@Override
public Object doInOperations(KafkaOperations kafkaOperations) {
kafkaOperations.send(topic, content);
throw new RuntimeException("fail");
// return true;
}
});
}
}消费者的更多使用方法
1. 指定 topic、partition、offset 消费
前面我们只监听了 topic1,监听的是所有在 topic1 上的消息,我们还可以指定 topic、partition、offset,在@KafkaListener注解上全部为我们提供了
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
**/
@Component
class KafkaConsumer{
@KafkaListener(id = "consumer1",groupId = "felix-group",topicPartitions = {
@TopicPartition(topic = "topic1",partitions = {"0"}),
@TopicPartition(topic = "topic2",partitions = "0",partitionOffsets = @PartitionOffset(partition = "1",initialOffset = "8"))
})
public void handleMessage(ConsumerRecord record){
System.out.println("============"+record.topic()+"->"+record.partition()+"->"+record.value()+"============");
}
}- id:消费者 ID
- groupid:消费组 ID
- topics:监听的 topic,可以监听多个
- topicPartitions:可以配置更加详细的监听信息,可以指定 topic、parition、offset 监听
上面 handleMessage 监听的含义:监听 topic1 的 0 号分区,同时监听 topic2 的 0 号分区和 topic2 的 1 号分区里面 offset 从 8 开始的消息。
注意:topics 和 topicPartitions 不能同时使用;
2. 批量消费
修改配置文件,开启批量消费
# 设置批量消费
spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50接收消息时使用 List 来接收,监听代码如下
@KafkaListener(topics = "topic1")
//也可以使用List<ConsumerRecord<?, ?>>
public void onMessage3(ConsumerRecords<?, ?> records) {
System.out.println(">>>批量消费一次,records.size()="+records.count());
for (ConsumerRecord<?, ?> record : records) {
System.out.println(record.value());
}
}3. 异常处理器
通过异常处理,我们可以处理 consumer 在消费时发生的异常。
创建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,使用@Bean 注入,然后将这个异常处理的 BeanName 放到@KafkaListener 注解的 errorHandler 属性里面,当监听抛出异常的时候,则会自动调用异常处理器
@Bean
public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() {
return (message, exception, consumer) -> {
System.out.println("消费异常:"+message.getPayload());
return null;
};
}@KafkaListener(topics = {"topic1"},errorHandler = "consumerAwareErrorHandler")4. 消息过滤器
// 监听器工厂
@Autowired
private ConsumerFactory consumerFactory;
// 配置一个消息过滤策略
@Bean
public ConcurrentKafkaListenerContainerFactory myFilterContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(consumerFactory);
// 被过滤的消息将被丢弃
factory.setAckDiscarded(true);
// 消息过滤策略(将消息转换为int类型,判断是奇数还是偶数,把所有奇数过滤,监听器只接收偶数)
factory.setRecordFilterStrategy(consumerRecord -> {
if (Integer.parseInt(consumerRecord.value().toString()) % 2 == 0) {
return false;
}
//返回true消息则被过滤
return true;
});
return factory;
}@KafkaListener(topics = "topic1",containerFactory = "myFilterContainerFactory")上面实现了一个”过滤奇数、接收偶数”的过滤策略,我们向 topic1 发送 0-99 总共 100 条消息,看一下监听器的消费情况,可以看到监听器只消费了偶数
5. 消息转发
在实际开发中,我们可能有这样的需求,应用 A 从 TopicA 获取到消息,经过处理后转发到 TopicB,再由应用 B 监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
在 SpringBoot 集成 Kafka 实现消息的转发也很简单,只需要通过一个@SendTo 注解,被注解方法的 return 值即转发的消息内容,如下:
@Component
class KafkaConsumer {
@KafkaListener(topics = "topic1")
@SendTo("topic2")//使用前需要配置KafkaTemplate,有点麻烦,实在需要的话照着官方文档复制粘贴就好了
public String handleMessage(ConsumerRecord<?, ?> record) {
// System.out.println(record.value()+"->topic1");
return record.value()+"-forward message";
}
@KafkaListener(topics = "topic2")
public void handleMessage2(ConsumerRecord<?, ?> record) {
System.out.println(record.value()+"->topic2");
}
}6. 定时启动、停止监听器
默认情况下,当消费者项目启动的时候,监听器就开始工作,监听消费发送到指定 topic 的消息,那如果我们不想让监听器立即工作,想让它在我们指定的时间点开始工作,或者在我们指定的时间点停止工作,该怎么处理呢——使用 KafkaListenerEndpointRegistry,下面我们就来实现:
禁止监听器自启动;
创建两个定时任务,一个用来在指定时间点启动定时器,另一个在指定时间点停止定时器;
新建一个定时任务类,用注解@EnableScheduling 声明,KafkaListenerEndpointRegistry 在 SpringIO 中已经被注册为 Bean,直接注入,设置禁止 KafkaListener 自启动,
@EnableScheduling
@Component
public class CronTimer {
/**
* @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean,
* 而是会被注册在KafkaListenerEndpointRegistry中,
* 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean
**/
@Autowired
private KafkaListenerEndpointRegistry registry;
@Autowired
private ConsumerFactory consumerFactory;
// 监听器容器工厂(设置禁止KafkaListener自启动)
@Bean
public ConcurrentKafkaListenerContainerFactory delayContainerFactory() {
ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory();
container.setConsumerFactory(consumerFactory);
//禁止KafkaListener自启动
container.setAutoStartup(false);
return container;
}
// 监听器
@KafkaListener(id="timingConsumer",topics = "topic1",containerFactory = "delayContainerFactory")
public void onMessage1(ConsumerRecord<?, ?> record){
System.out.println("消费成功:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
// 定时启动监听器
@Scheduled(cron = "0 42 11 * * ? ")
public void startListener() {
System.out.println("启动监听器...");
// "timingConsumer"是@KafkaListener注解后面设置的监听器ID,标识这个监听器
if (!registry.getListenerContainer("timingConsumer").isRunning()) {
registry.getListenerContainer("timingConsumer").start();
}
//registry.getListenerContainer("timingConsumer").resume();
}
// 定时停止监听器
@Scheduled(cron = "0 45 11 * * ? ")
public void shutDownListener() {
System.out.println("关闭监听器...");
registry.getListenerContainer("timingConsumer").pause();
}
}参考文章:
Kafka:http://kafka.apache.org/
Kafka 原理架构:点击链接
文章:https://blog.csdn.net/yuanlong122716/article/details/105160545/
SpringBootKafka:https://docs.spring.io/spring-kafka/docs/current/reference/html/#preface