雪花算法
算法原理
SnowFlake算法生成id的结果是一个65bit大小的整数(Long),它的结构如下图:
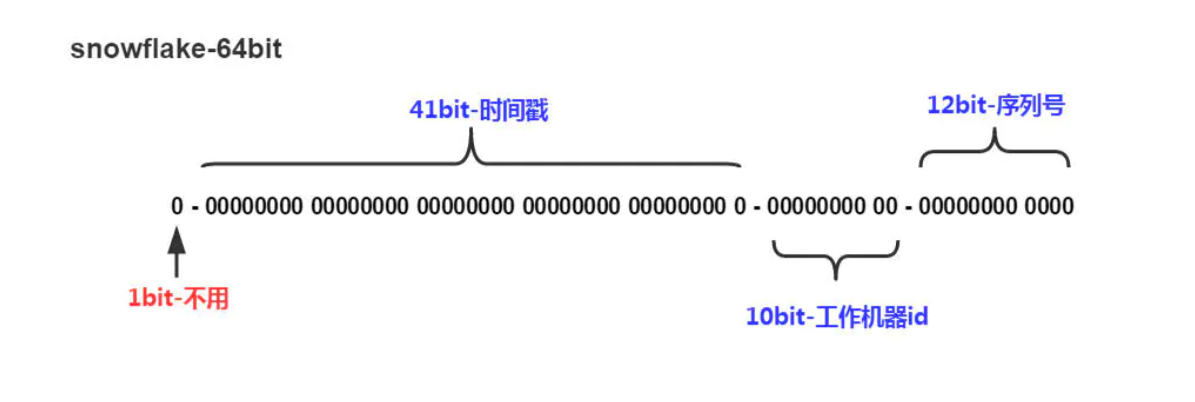
- 1bit:不用,二进制中最高位是符号位,1表示负数,0表示正数,生成的id一般都是正数,所以固定为0。
- 41bit:用来记录时间戳,毫秒级。
- 41位表示 2^41 - 1 个数字
- 如果只用来表示正整数(包含0),可以表示的数值范围是:0 至 2^41 - 1,减 1 是因为可表示的数值范围是从 0 开始,而不是 1
- 也就是说 41 位可以表示 2^41 - 1个毫秒的值,转化成单位年则是 69 年
- 10bit:用来记录工作机器ID。
- 可以部署在2^10 = 1024个节点,包括5位datacenterId和5位workerId
- 5bit:可以表示最大正整数为 2^5 - 1 = 31,即可以用 0 - 31 这些数字来表示不同的datacenterId或workerId
- 这 10bit 更多的是结合实际业务情况而定的
- 12bit:序列号,同来记录同一毫秒内产生的不同id。
- 12bit可以表示的最大正整数是 2^12 - 1 = 4095,即 0 - 4094这些数字,来表示同一机器同一时间戳(毫秒内)产生的4095个id序列号
在Java中64bit的整数只有long类型,所以在java中SnowFlake算法生成的id就是long来存储的。
SnowFlake可以做到:
- 所有生成的id按时间趋势递增
- 整个分布式系统内不会产生重复id(因为有datacenterid和workerId来区分)
Java实现
public class IdWorker {
//下面两个每个5位 加起来就是10位的工作机器ID
private long workerId;//工作ID
private long datacenterId;//数据ID
//12位序列号
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("workerId 不能大于 %d 或小于 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter 不能大于 %d 或小于 0", maxDatacenterId));
}
System.out.printf("工作开始,tiimestamp 左移 %d,datacenterIdBits %d,workerIdBits %d,sequenceBits %d,workerId %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
//初始时间戳
private long twepoch = 1288834974657L;
//长度为5位
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//最大值
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号id长度
private long sequenceBits = 12L;
//序列号最大值
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//工作ID需要左移的位数 12位
private long workerIdShift = sequenceBits;
//数据ID需要左移的位数 12+5=17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳需要左移位数 12+5+5=22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//上次时间戳 初始值为负数
private long lastTimestamp = -1L;
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
//下一个ID生成算法
public synchronized long nextId() {
long timestamp = timeGen();
//获取当前时间戳如果小于上次时间戳,则表示时间戳获取异常
if (timestamp < lastTimestamp) {
System.out.printf("时间倒转,拒绝请求 %d", lastTimestamp);
throw new RuntimeException(String.format("时间倒转,拒绝生成 id 到 %d 毫秒", lastTimestamp - timestamp));
}
//获取当前时间戳如果等于上次时间错(同一毫秒内),则在序列号加一,否则序列号赋值为0,从0开始
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
//将上次时间戳刷新
lastTimestamp = timestamp;
/**
* (timestamp - twepoch) << timestampLeftShift 表示将时间戳减去初始时间戳,在左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应的位数
* (workerId << workerIdShift) 表示将工作id左移相应的位数
* | 是按位或运算,例如:x | y,只有x,y都为0时结果才为0,其他情况结果都为1.
* 因为个部位子行业相应位上的值有意义,其他位都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;
}
//获取时间戳,并与上次时间戳比较
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取系统时间戳
private long timeGen() {
return System.currentTimeMillis();
}
//使用
public static void main(String[] args) {
IdWorker worker = new IdWorker(1,1,1);
for (int i = 0; i < 4096; i++) {
System.out.println(worker.nextId());
}
}
}简单的概括上面代码:
- 其实就是把一堆数字的二进制码按照相对应的顺序组合在一起,形成一个64bit的二进制码,而这个二进制数字对应一个 Long 类型的整数,而因为这些数字的特殊性,得出的结果不会重复。
参考
文章1:https://www.jianshu.com/p/2a27fbd9e71a
文章2:https://blog.csdn.net/lq18050010830/article/details/89845790
文章3:https://segmentfault.com/a/1190000011282426
Twitter官方实现(Scala):Twitter官方实现