
Rabbit
RabbitMQ是一个由Erlang开发的AMQP的开源实现,能够实现异步消息处理,有效的降低代码耦合,学习成本低,支持多语言
不同MQ的区别
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 成熟度 | 成熟 | 成熟 | 比较成熟 | 成熟的日志领域 |
| 时效性 | 微秒级 | 毫秒级 | 毫秒级 | |
| 社区活跃度 | 低 | 高 | 高 | 高 |
| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 10万级,RocketMQ也是可以支撑高吞吐的一种MQ | 10万级别,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic从几十个到几百个的时候,吞吐量会大幅度下降所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 | ||
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,分布式架构 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用 |
| 优劣势总结 | 非常成熟,功能也强大,偶尔有概率丢失信息,国内用的越来越少 | Erlang开发,性能很好,延迟低,吞吐量还行,功能完备,还有图形界面,社区活跃,国内用的越来越多,但是Erlang开发国内很难掌控,集群动态扩展麻烦 | 简单易用,阿里撑腰 | 有对消息重复消费的风险,其他都还行,在日志采集领域应用大 |
架构设计
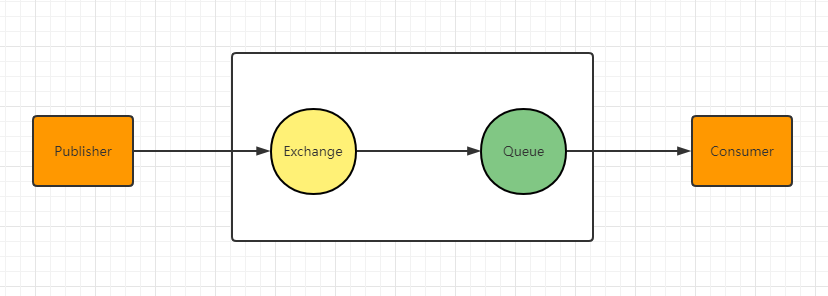
Publish - 生产者 - 发布消息到 RabbitMQ 中的 Exchange
Exchange - 交换机 - 与 Publish 建立连接并接收 Publish 的消息
Routes - 路由 - 交换机以什么样的策略将消息发布到 Queue
Queue - 队列 - Exchange 会将消息分发到指定的 Queue,Queue 和 Consumer 进行交互
Consumer - 消费者 - 监听 RabbitMQ 中的 Queue 中的消息
简单架构图
完整架构图
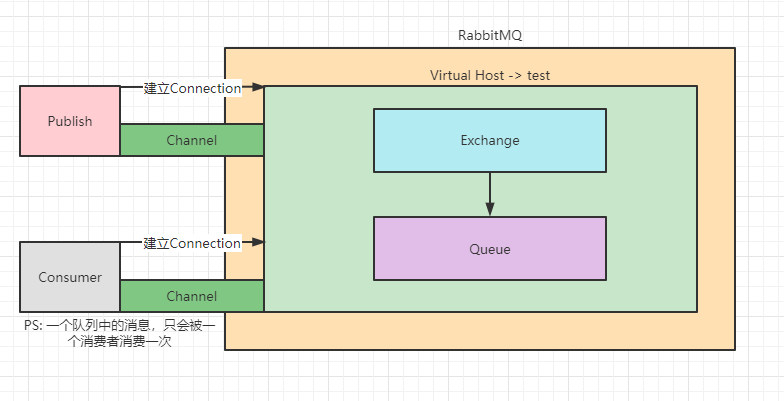
Virtual Host:相当于 RabbitMQ 上的虚拟机,可以创立多个,不同用户可以指定连接不同的 Virtual Host

Exchange (交换机) 类型
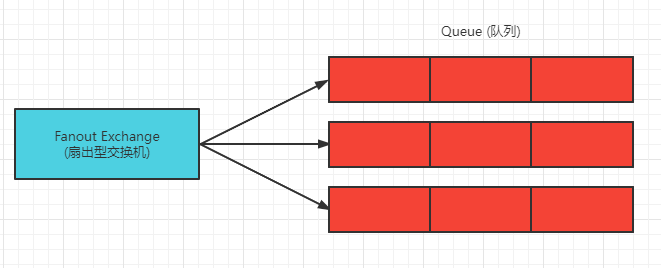
Fanout (扇出)
扇出型交换机路由规则非常简单,它不处理路由键,该交换机会把消息路由到所有与本交换机绑定的队列上
如图所示:交换机把接收到的消息发送到所有队列中
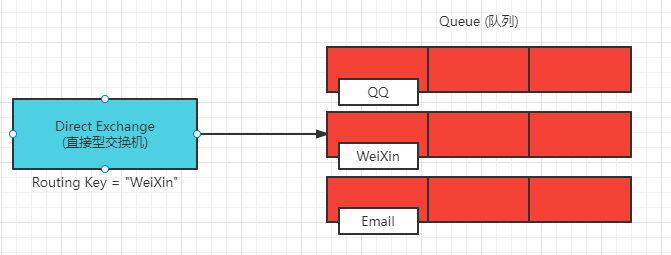
Direct (直接)
直接型交换机需要和 Routing Key 打交道了,在交换机接收到带有 Routing Key 的消息后,会与交换机和队列之间的 Binding 路由规则进行匹配,当 Routing Key 与 Binding Key 完全匹配后,会将消息路由到匹配的队列上
如图所示:带有 Routing Key = “WeiXin” 的消息被发送到交换机后,交换机与第二个队列中设置的路由规则匹配上,所以将消息发送到了第二个队列中
Topic (主题)
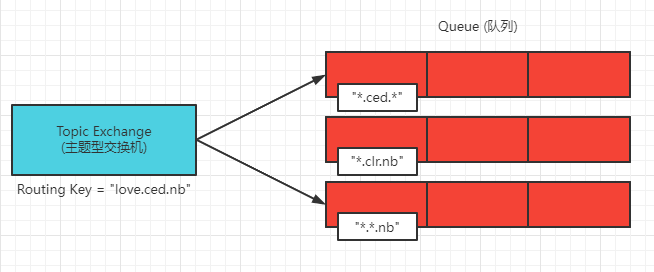
主题型交换机是对 Direct(直接)型交换机的升级,当直接型交换机的严格匹配不能满足需求时,就可以使用主题型交换机,主题型交换机是可以在 Routing Key 与 Binding Key 匹配时进行进行模糊匹配的,符号”#”匹配一个或多个词,符号”*”只能匹配一个词
如图所示:Routing Key 的值为”love.ced.nb”的消息发送到交换机,交换机会根据 Binding Key 中的规则进行模糊匹配,所以第一个和第三个是满足条件的,所以将消息发送到了这两个队列中
Headers (标题)
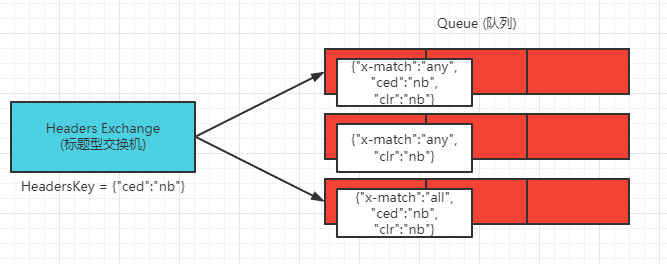
标题型交换机不对 Routing Key 进行匹配,而是根据消息内容中的 Headers 属性进行匹配,在对 Exchange 与 Queue 进行绑定时设置一组键值对,当消息发送到交换机后,RabbitMQ 会取出该消息的 Headers 属性,对其中的键值对与绑定的键值对进行匹配,交换机会将消息路由到匹配成功的队列中,标题型交换机设置的键值对可以是任意类型,而其他类型交换机的 Routing Key 则是字符串类型
如图所示:带有 “ced” : “nb” Headers属性的消息发送到交换机后,交换机根据与每个队列设置的键值对进行匹配,第一个和第三个可以匹配成功,所以将消息发送到这两个队列中
六种模式
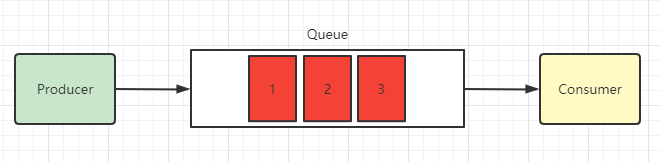
Simple (简单模式)
一个队列,一个消费者,一个队列的消息只能被一个消费者消费
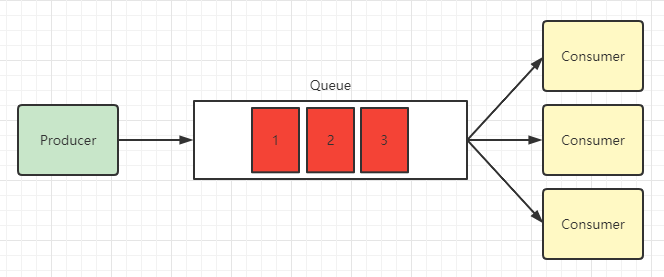
Work (工作模式)
一个队列,多个消费者,一个队列将消息发送给多个消费者,每个消费者处理不同的消息
工作模式还分两种方式:
公平分发
公平分发就是轮询分发,消费者收到的消息数量基本上是一样的
不公平分发
不公平分发就是按照消费者的能力来发送,处理速度快的多处理,处理速度慢的少处理
Publish/Subscribe (订阅模式)
订阅模式队列将消息分发给多个消费者,每个消费者都对应自己的队列,当消息发送到交换机,交换机会将消息发送给所有队列中,RabbitMQ 将队列中的消息发给指定消费者
交换机类型设置为 Fanout(扇出) 类型
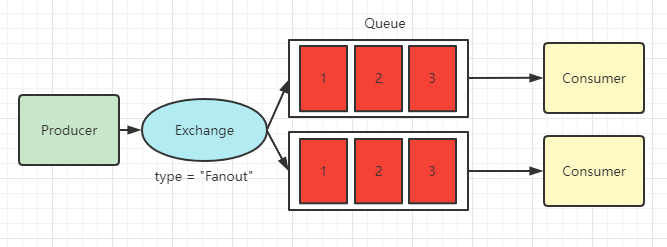
Routing (路由模式)
路由模式是发布订阅的升级,每个消费者也是有自己的指定队列,只是在交换机将消息发送到队列时需要进行规则匹配,只有匹配之后,RabbitMQ才会将消息分发给对应的队列
交换机类型设置为 Direct(直连) 类型
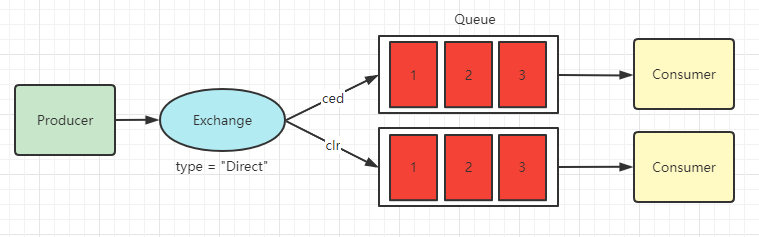
Topic (主题模式)
主题模式是 Routing 模式的升级,在路由规则中加入了模糊匹配,根据模糊匹配的结果将消息分发到对应的消费者
交换机类型设置为 Topic(主题) 类型
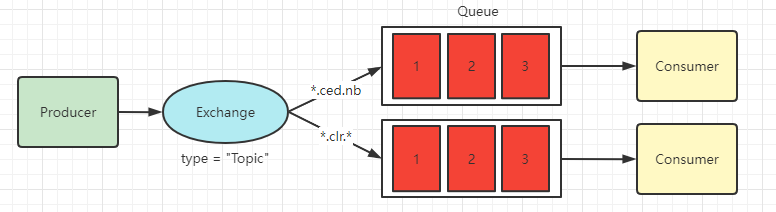
RPC (RPC模式)
TODO
ACK确认机制
消息一旦被消费者接收,队列中的消息就会被删除
那么问题来了:RabbitMQ怎么知道消息被接收了呢?
如果消费者领取消息后,没有来得及消费挂掉了呢?或者抛出了异常,消息处理失败,RabbitMQ无法得知,消息就丢失了
因此,RabbitMQ有ACK应答机制,当消费被消费者获取后,会向RabbitMQ发送回执ACK,告知消息已经被接收,这种ACK有两种:
自动ACK:消息一旦被接收,消费者自动发送ACK
手动ACK:消息接收后,需要手动发送ACK
当消息不太重要时,使用自动ACK足以,当消息非常重要,最好使用手动ACK,在消息被消费完成后删除
@Slf4j
@Component
@RabbitListener(queues = "confirm_test_queue")
public class ReceiverMessage1 {
@RabbitHandler
public void processHandler(String msg, Channel chnnel, Message message) throws IOException {
try {
log.info("收到消息:{}", msg);
//TODO 具体业务
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
if (message.getMessageProperties().getRedelivered()) {
log.error("消息已重复处理失败,拒绝再次接收...");
channel.basicReject(message.getMessageProperties().getDeliveryTag(), false); // 拒绝消息
} else {
log.error("消息即将再次返回队列处理...");
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, true);
}
}
}
}消费消息有三种回执方式:
basicAck
basicAck:表示成功确认,使用此回执方法后,消息会被rabbitmq broker删除
void basicAck(long deliveryTag, boolean multiple) deliverTag:表示消息投递序号,,每次消费消息或消息重复投递后,deliveryTag都会增加,手动确认模式下,我们可以对指定deliveryTag的消息进行ack、nack、reject等操作
multiple:是否批量确认,值为true时,会一次性ack所有小于当前消息deliverTag的消息
basicNack
basicNack:表示失败确认,一般在消费消息业务异常时用此方法,可以将消息重新投递到队列中
void basicNack(long deliveryTag, boolean multiple, boolean requeue)deliverTag:表示消息投递序号
multiple:是否批量确认
requeue:值为 true 消息将重新入队列。
basicReject
basicReject:拒绝消息,与basicNack区别在于不能进行批量操作,其他用法很相似。
void basicReject(long deliveryTag, boolean requeue)deliveryTag:表示消息投递序号。
requeue:值为 true 消息将重新入队列。
Confirm机制
消息只要被RabbitMQ Broker接收到就会触发ConfirmCallback回调
@Component
public class ConfirmCallbackService implements RabbitTemplate.ConfirmCallback {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if (!ack) {
log.error("消息发送异常!");
} else {
log.info("发送者已经收到确认,correlationData={} ,ack={}, cause={}", correlationData.getId(), ack, cause);
}
}
}实现接口ConfirmCallback,重写confirm()方法,方法内有三个参数correlationData、ack、cause
correlationData:对象内部只有id属性,用来表示消息的唯一性ack:消息投递到broker的状态,true表示成功cause:表示消息投递失败的原因
消息被broker接收到只能表示已经到达MQ服务器,并不能保证消息一定会被投放到目标queue中,所以还有returnCallback机制
Return机制
如果消息未能投递到目标queue中,将会触发回调returnCallback,一旦向queue投递消息失败,这里会记录下当前消息的详细投递数据,方便后续操作
PS:Return的回调是优先于Confirm的
在实际使用时,需要格外注意一点,如果消息没有匹配到合适的队列,触发了Return,然后接着触发Confirm时,Confirm是呈现一个成功的状态,这时候需要小心消息丢失,解决方法可参照:http://t.zoukankan.com/pokid-p-10527765.html
@Component
public class ReturnCallbackService implements RabbiTemplate.ReturnCallback {
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
log.info("returnedMessage ===> replyCode={} ,replyText={} ,exchange={} ,routingKey={}", replyCode, replyText, exchange, routingKey);
}
}
//必须设置为 true,不然当 发送到交换器成功,但是没有匹配的队列,不会触发 ReturnCallback 回调
//而且 ReturnCallback 比 ConfirmCallback 先回调,意思就是 ReturnCallback 执行完了才会执行 ConfirmCallback
rabbitTemplate.setMandatory(true);实现接口ReturnsCallback,重写returnedMessage(),方法有五个参数,最新版中,只包含一个message(消息体)、replyCode(响应code)、replyText(响应内容)、exchange(交换机)、routingKey(队列)ReturnedMessage类型参数,基本上是对前者的封装
延迟队列
延迟队列,即消息进入队列之后不会立即消费,只有到达指定时间后,才会被消费,但是,在RabbitMQ中未提供延迟队列功能,但是可以通过 TTL + 死信队列实现
TTL
TTL,全称 Time To Live,消息过期时间设置,消息的TTL就是消息存活的时间,RabbitMQ可以对队列和消息分别设置TTL
队列:对队列设置就是队列没有消费者连着的保存时间
消息:对消息设置就是超过这个时间,我们就认为这个消息死了,称之为死信
队列过期后,会将队列所有的消息移除,一个队列中某一个消息过期后,**只有消息在队列顶端,才会判断是否过期(移除)**,如果不是在队列顶端,那么是无效的,过期时间由队列的过期时间判定
如果队列设置了,消息也设置了,那么会取时间最短的,所以一个消息如果被路由到不同队列中,它们的死亡时间可能不一样
死信队列
死信队列,英文:DLX(Dead Letter Exchange),当消息成为Dead Message后,可以被重新发送到另一个交换机,这个交换机就是DLX
消息成为死信的三种情况:
队列消息长度达到限制
消费者拒绝消费消息,
basicNack/basicReject,并且不把消息重新放入原目标队 列,requeue=false原队列存在消息过期设置,消息超时未被消费
实现
延迟队列通过消息的TTL和DLX来实现,我们需要建立两个队列,一个用于发消息,一个用于消息过期后的转发目标队列

配置两个消息队列:一个是普通队列,一个是死信队列
@Configuration
public class RabbitmqConfig {
/**
* 普通队列
*
* @return
*/
@Bean
public Queue queueWork() {
Map<String, Object> args = new HashMap<>();
//设置消息过期时间
args.put("x-message-ttl", 1000 * 10);
//设置死信交换机
args.put("x-dead-letter-exchange", "dlx_exchange");
//设置死信 routing_key
args.put("x-dead-letter-routing-key", "dlx_routing_key");
return new Queue("queue_work", true, false, false, args);
}
/**
* 死信队列
* @return
*/
@Bean
public Queue queueDLX() {
return new Queue("dlx_queue", true, false, false);
}
/**
* 死信交换机
* @return
*/
@Bean
public DirectExchange exchangeDLX() {
return new DirectExchange("dlx_exchange", true, false);
}
/**
* 绑定死信队列和死信交换机
* @return
*/
@Bean
public Binding dlxBinding() {
return BindingBuilder.bind(queueDLX()).to(exchangeDLX())
.with("dlx_routing_key");
}
}配置一个死信队列消费者
@Component
public class WorkReceiveListener {
@RabbitListener(queues = "dlx_queue")
public void handle(String msg, Channel channel, Message message) {
System.out.println(msg);
}
}收到消息后将其打印出来,整个实现过程十分简单
还有一个方式是通过安装RabbitMQ实现的,这里不做赘述,可参考:RabbitMQ 实现延迟队列的两种方式
消息丢失问题
MQ丢失数据,有以下场景:
生产者丢失数据
- RabbitMQ:生产者发送数据到 RabbitMQ 时,传输过程中丢失数据
MQ自己丢失数据
- RabbitMQ:如果 RabbitMQ 没有开启持久化,那么一旦重启,数据将会丢失
消费者丢失数据
- RabbitMQ:消费者消费时,还没有处理,消费者挂了,重启之后,导致数据丢失
解决方法:
生产者端:
开启事务 PS:事务开启时,会变成同步阻塞操作,生产者会阻塞等待是否发送成功,耗费性能
开启 Confirm 模式,通过 ACK 机制确认发送是否成功
RabbitMQ端:
设置持久化 Queue
发送消息时,将消息的 deliveryModel 设置尾 2,消息会被持久化到硬盘
以上两点需要同时开启才有保证
消费者端:
- 使用 RabbitMQ 提供的 ACK 机制,首先关闭 RabbitMQ 的自动ACK,然后确保处理完消息之后,在代码中手动调用ACK
重复消费问题
造成消息重复的两个原因是:网络不可达、消费端宕机。无法避免这两个问题,解决方法就是绕过这个问题。
问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
解决方法:
send if not exist
首先将
RabbitMQ的消息自动确认机制改为手动确认,然后每当有一条消息消费成功了,就把该消息的唯一ID记录在Redis上,然后每次发送消息时,都先去Redis上查看是否有该消息的 ID,如果有,表示该消息已经消费过了,不再处理,否则再去处理。insert if not exist
可以通过给消息的某一些属性设置唯一约束,比如增加唯一
uuid,添加的时候查询是否存对应的uuid,存在不操作,不存在则添加,那样对于相同的uuid只会存在一条数据sql乐观锁
比如给用户发送短信,变成如果该用户未发送过短信,则给用户发送短信,此时的操作则是幂等性操作。但在实际上,对于一个问题如何获取前置条件往往比较复杂,此时可以通过设置版本号
version,每修改一次则版本号+1,在更新时则通过判断两个数据的版本号是否一致
参考
SpringBoot整合:https://blog.csdn.net/fan521dan/article/details/104912794
文章1:https://blog.csdn.net/qq_45472675/article/details/110951399
文章2:https://blog.csdn.net/cuierdan/article/details/123824300
文章3:https://blog.csdn.net/kavito/article/details/91403659
文章4:https://juejin.cn/post/6844904205438681095
文章5:https://blog.csdn.net/weixin_44273388/article/details/124285031