
HBase初步学习
什么是HBase
HBase是一个面向列式存储的分布式数据库,底层实现基于HDFS实现,集群管理基于ZooKeeper实现,具有良好的分布式架构设计,为海量数据存储的快速存储、随机访问提供了可能,基于数据副本机制和分区机制,可以轻松实现在线扩容、缩容和数据容灾,是大数据 Key-Value 数据结构存储的常用解决方案
HBase模块组成
HBase可以将数据存储在本地文件系统,也可以存储在HDFS文件系统,在生存环境中,HBase一般运行在HDFS上,以HDFS作为基础的存储设施,HBase通过HBase Client提供的Java API访问HBase数据库,已完成数据的写入和读取,HBase集群主要由HMaster、Region Server和ZooKeeper组成
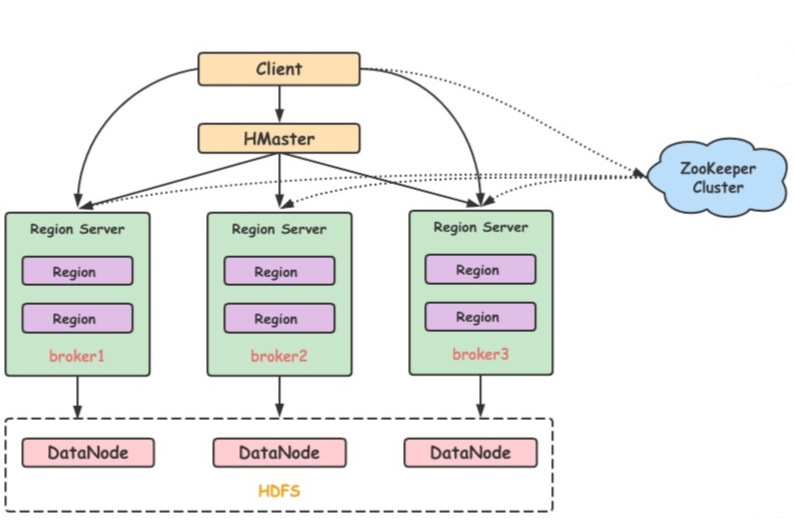
HMaster
负责管理
RegionServer,实现负载均衡管理和分配
Region,比如在Region Split时分配新的Region,在RegionServer退出时迁移内部的Region到其他RegionServer上管理
Namespace和Table的元数据(实际存储在HDFS上)权限控制
RegionServer
存放和管理本地
Region读写
HDFS,管理Table中的数据Client从HMaster中获取元数据,找到RowKey所在的RegionServer进行读写数据
ZooKeeper
存放整个
HBase集群的元数据以及集群的信息状态实现
HMaster主从节点的Failover
HBase数据模型
HBase是一个面向列式存储的分布式数据库。HBase的数据模型与BigTable十分相似。在 HBase表中,一条数据拥有一个全局唯一的键RowKey和任意数量的列Column,一列或多列组成一个列族Column Family,同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。 HBase 中的表是疏松地存储的,因此用户可以动态地为数据定义各种不同的列。HBase中的数据按主键排序,同时,HBase会将表按主键划分为多个Region存储在不同RegionServer上,以完成数据的分布式存储和读取。
HBase根据列成来存储数据,一个列族对应物理存储上的一个HFile,列族包含多列列族在创建表的时候被指定。
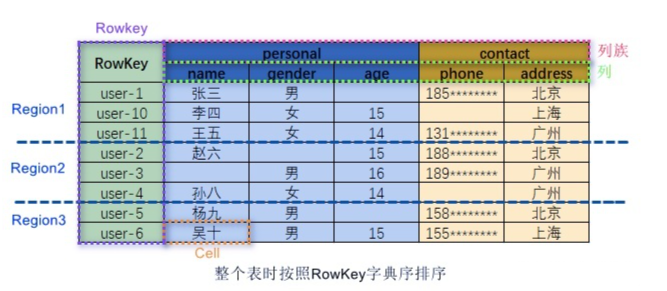
ColumnFamily
ColumnFamily即列族,HBase基于列族划分数据的物理存储,一个列族可以包含多列一般同一类的列会放在一个列族,每个列族都有一组存储属性:
是否应该缓存在内存中
数据如何被压缩或行键如何编码等
HBase在创建表的时候就必须指定列族,列族最好小于等于3个,过多不方便管理和索引RowKey
RowKey的概念和传统关系型数据库中的主键相似,HBase使用RowKey来唯一标识某行的数据访问
HBase数据的方式有三种:基于
RowKey的单行查询基于
RowKey的范围查询全表扫描查询
Region
HBase将表中的数据基于RowKey的不同范围划分到不同的Region上,每个Region都负责一定范围的数据存储和访问每个表开始只有一个
Region,随着数据不断插入表,Region不断增大,当增大到一个阙值的时候,Region就会分成两个新的Region另外,
Region是HBase中分布式存储和负载均衡的最小单元,不同的Region分布在不同的RegionServer上这样就方便了大量数据下的并发操作,访问数据速度不会有太大降低
TimeStamp
TimeStamp是实现
HBase多版本的关键,在HBase中,使用不同的TmeStamp来标识相同RowKey对应不同的版本的数据,相同的RowKey的数据按照TimeStamp倒叙排列,默认查询最新版本,当然也可以用户指定查询
底层设计
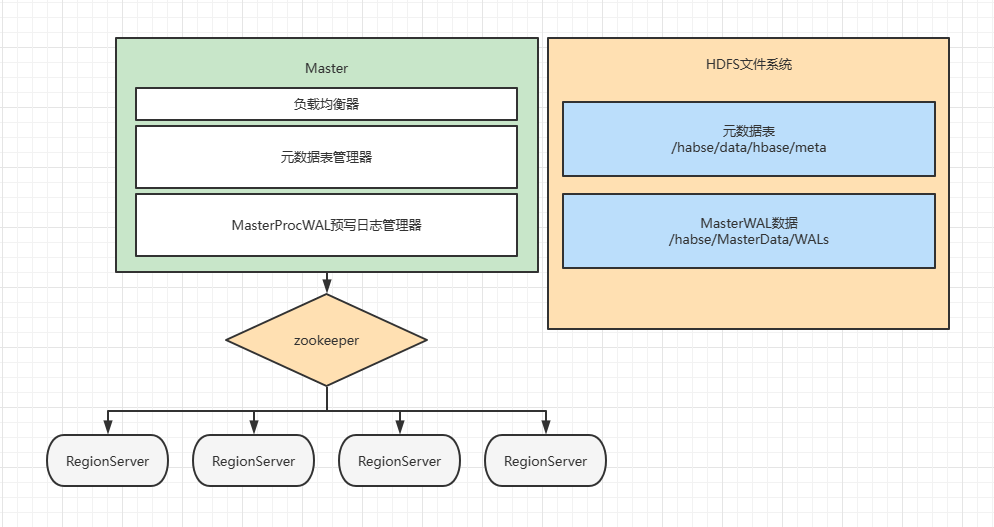
Master
主要的进程,具体实现类为HMaster
通常部署在namenode上
主要包含3个部件
负载均衡器
读取
Meta表了解Region的分配,通过zk了解RS的启动情况,每5分钟调控一次分配平衡元数据表管理器
负责管理
Meta表的数据MasterProcWAL预写日志管理器负责管理
Master自己的预写日志,如果宕机,让BackUpMaster读取日志数据本质是写数据到
HDFS,文件到达32M或一小时滚动,当操作执行到Meta表之后删除WAL
PS:客户端只有在操作元数据时才会和Master建立连接,也就是getAdmin(),操作其他表数据时,是直接通过zookeeper与Region互动,也就是getTable()
RegionServer
主要的进程,具体实现类为HRegionServer
通常部署在dataNode上
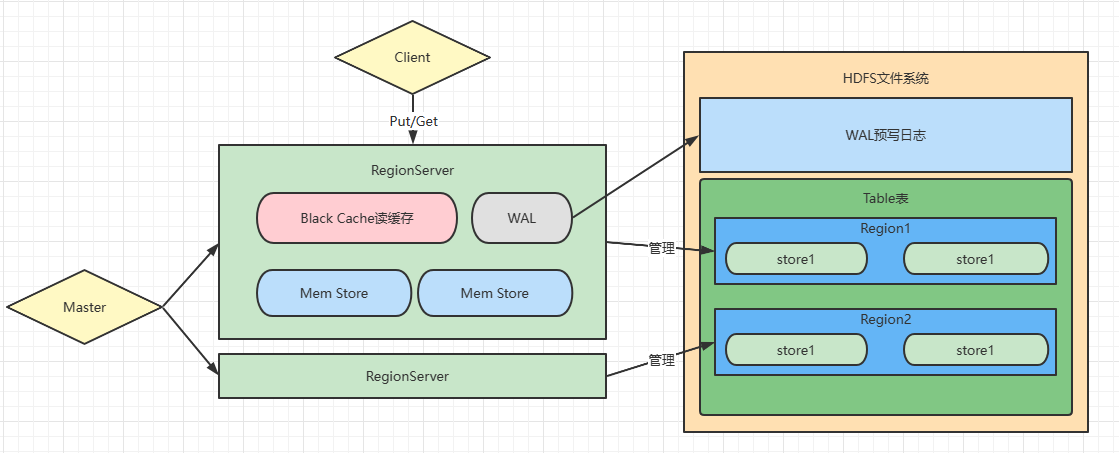
MemStore的数量取决RegionServer管理了多少个Store
Client写入数据时,会先写入MemStore,然后再写入Store中(这一步主要的为了根据RowKey排序),所以WAL预写日志就是为了防止MemStore数据还没写入到Store时Master就挂了而准备的
除了一些必要的组件,还会启动一些线程监控必要的服务:
Region拆分Region的合并MemStory书写WAL预写日志的滚动
写流程
写流程从客户端创建连接开始,到最终刷写落盘道HDFS上结束
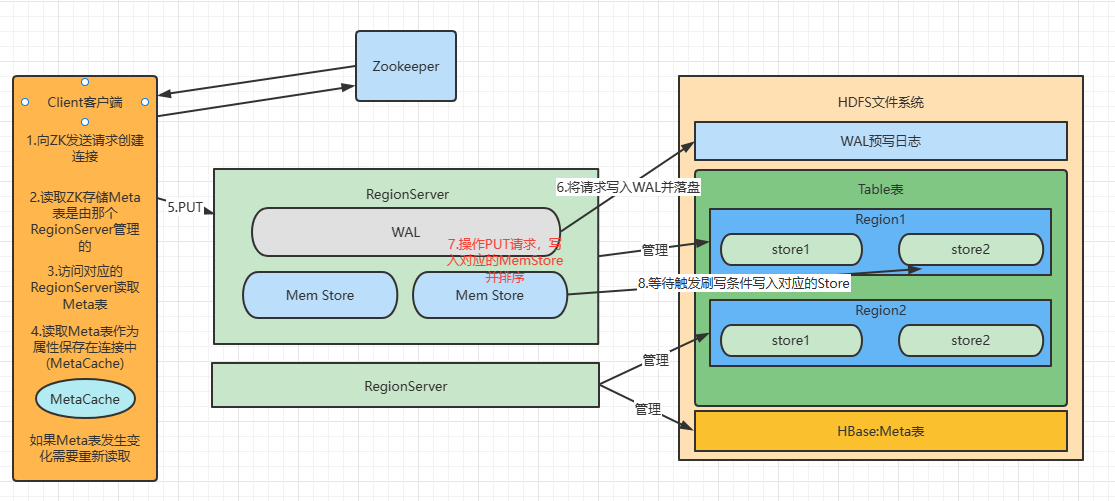
先写入WAL的原因是数据在MemStore会排序并保存一段时间,存内存是不安全的
数据在写入MemStore之后会返回写入成功的ACK,此时宕机可以通过WAL找回
写流程顺序正如API编写顺序
创建
HBase重量级连接首先访问
Zookeeper,获取HBase:Meta表位于哪个RegionServer访问对应的
RegionServer,获取HBase:Meta表,将其缓存到连接中,作为连接属性MetaCache,由Meta表格具有一定的数据量,导致创建连接比较慢之后创建连接获取
Table,这是一个轻量级连接,只有在第一次创建的时候会检查表格是否存在访问RegionServer,之后在获取Table时不会访问RegionServer调用
Table的Put方法写入数据,此时还需要解析RowKey,对照缓存MetaCache,查看具体写入的位置有有哪个RegionServer将数据顺序写入(追加)到WAL,此处写入是直接落盘的,并设置专门的线程控制WAL预写日志的滚动
读流程
读流程从客户端创建连接开始,到合并数据返回客户端结束
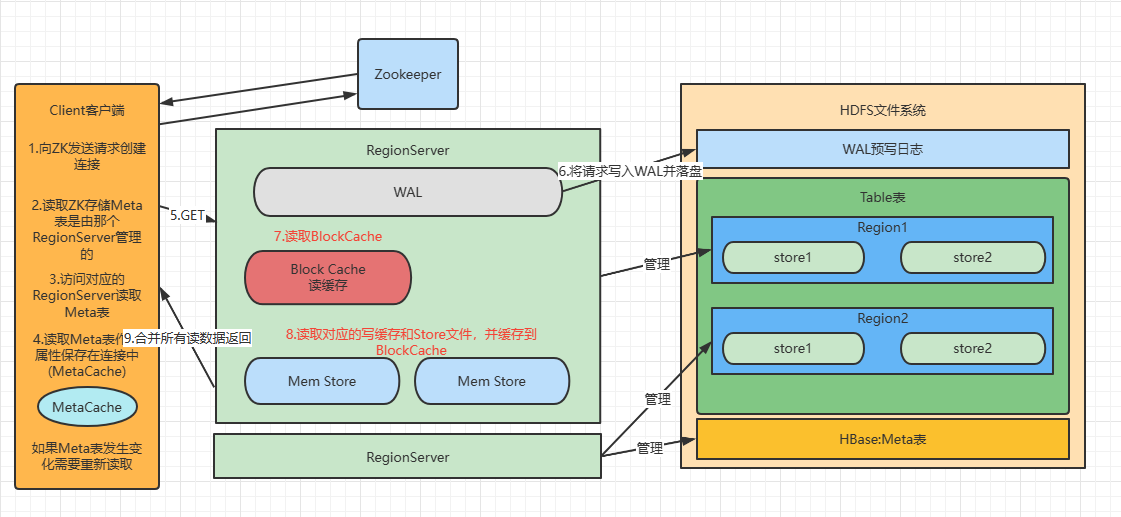
读流程同写流程差不多
创建
Table对象发送Get请求优先访问
BlockCache,查找是否之前读取过,并且可以读取HFile的索引信息和布隆过滤器不管读缓存是否已经有数据(可能已经过期了),都需要再次读取写缓存和
Store中的文件最终将所有读取到的数据合并版本,按照
Get的要求返回即可
RowKey的设计
HBase中RowKey可以唯一表示一行记录,在HBase查询时有以下方式:
通过
Get方式,指定RowKey获取唯一记录通过
Scan方法,设置startRow和stopRow进行范围匹配全表扫描
RowKey在增删改查中充当主键的作用,它可以是任意字符串,在HBase中RowKey会保存为字节数组
HBase中数据是按照RowKey的ASCII字典顺序进行全局排序,因此,在设计RowKey时,要充分利用并意识到这个特性
HBase表的数据是按照RowKey来分散到不同的Region中的,不合理的RowKey设计会导致热点问题,大量的Client访问集群的一个或极少数节点,而其他节点普遍处于空闲状态
参数调优
Zookeeper会话超时时间调整
hbase-site.xml
属性:zookeeper.session.timeout
解释:默认值为
90000毫秒(90s),当某个RegionServer挂掉了,90s后Master上能察觉到,可适当减少此值,尽可能快的检查到RegionServer故障,可调整至20-30s同时可时代调整Client重试时间和重试次数
hbase.client.pause (默认100ms)
hbase.client.retries.number (默认15次)
设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为
30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值手动控制Major Compaction
hbase-site.xml
属性:hbase.hregion.majorcompaction
解释:默认值为
604800000秒(7天),MajorCompaction的周期,若关闭自动MajorCompaction,可将其设置为0如果关闭记得手动合并,因为大合并非常有意义
优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值
10737418240 (10G),如果需要运行HBase的MR任务,可以减小此值,因为应该region对应一个map任务,如果单个region过大,会导致map任务执行时间过长,该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个HFile优化HBase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:默认值
2097152 bytes (2M),用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之,一般我们需要设定一定的缓存大小,以达到减少RPC调用次数的目的指定scan.next扫描HBase获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定
scan.next方法获取的默认行数,值越大,消耗内存越大BlockCache占用RegionServer堆内存的比例
hbase-site.xml
属性:hfile.block.cache.size
解释:默认
0.4,读请求比较多的情况下,可适当调大MemStore占用RegionServer堆内存的比例
hbase-site.xml
属性:hbase.regionserver.global.memstore.size
解释:默认
0.4,写请求比较多的情况下,可适当调大
参考
文章1:https://zhuanlan.zhihu.com/p/522104503